Ursula Development Log #1
I share progress from February on my WIP book-ranking app Ursula, talk about the fractured landscape of book metadata, and map out my plans for the app
TL;DR
- Ursula (named for Ursula Le Guin) is an open-source and non-commercial book-ranking app I'm working on. Kinda like Goodreads (but hopefully not too much like it).
- You can find the source-code at github.com/ironman5366/ursula.
- I aim for there to be two distinguishing features:
- Stack-Ranking, inspired by Beli. Each book is definitively ranked in your list, rather than being given a star ranking. On Beli I find this is a much higher signal of how good a restaurant is - if a friend who eats out often ranks a restaurant in their top 10, I'm going to go!
- AI Recommendations. I already frequently ask ChatGPT questions like "If I like sprawling sci-fi epics like "A Fire Upon the Deep", what should I read next?" This should be easy to build into Ursula.
- Bonus points if I get my LLM proxy project Weatherwax involved in this.
- I'm giving myself a deadline: I want to have a public beta on the app store by April 1, 2024
- If anything about Ursula interests you, please reach out at will@willbeddow.com
The long version
It's been ~a month since I wrote my last post, so if I want to keep my 2024 resolutions, it's time to write another.
It's been a wonderful month - I've had a lot of time, recently, post-Waverly, to work on projects and travel. I'm writing this post from a hostel in the mountains, where I've been snowed in by a blizzard️. I'm fresh off of a week in San Francisco, where I was lucky to spend a lot of time talking to folks far smarter than me about AI, and get deep into diffusion models. And, of course, I've been working on Ursula. (I also totally remade this website, but that's another post). Here are some (very) early unpolished screenshots of Ursula:
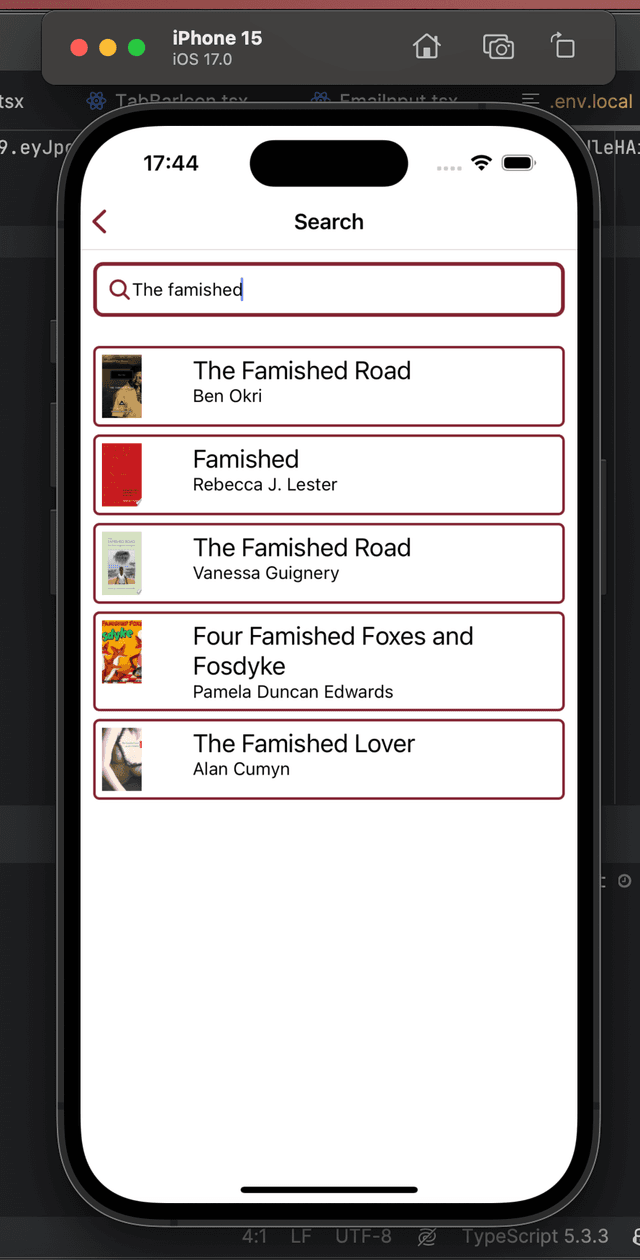


I'm really excited by Ursula; it has a well-defined and achievable goal ("binary search book rankings + ChatGPT recs") that many of my projects lack, and it's been years since I've published a side project in the open and tried to start getting users for it. The blogging, and giving myself the April 1st deadline, is really an outgrowth of this excitement - there's no technical or logistical reason that I shouldn't be able to get this app out before I'm gainfully employed again, and I want to align my incentives to make sure I do.
What's done so far:
- Basic app CRUD and setup on supabase
- Binary search to figure out where to put a book in the rankings
- Book search and google books integration
- Spend way too long browsing coolors.co for a color scheme
Next ~week roadmap:
- Get everything stable enough to dogfood with my friends
- Fill out the UI a little more
- Publish on TestFlight
- AI Recommendations
Longer term roadmap:
- Make the app look less like ass (I hear users like this)
- Switch to a different book metadata provider.
Challenges So Far: Book Metadata Sucks
When I started working on Ursula, I was deeply surprised to learn that there are no high-quality open data sources for book metadata (things like name, cover images, descriptions, author bios, etc.) available for programmatic use. Instead, there are a few free but closed providers with restrictive terms (like Google Books), and very expensive closed access to library catalogs (mostly via OCLC, a nonprofit consortium of libraries and institutions which share catalogs).
Besides their restrictive terms, Google Books and similar have quality and usability issues as well - for example, Google Books data is only organized by edition. If I don't write complicated backend code to group titles together, when you searched a book, you'd see every different edition of the book as a separate result.
OCLC / WorldCat has the highest quality by far, and they're the upstream data provider for Google Books, Goodreads, and, from what I can tell, most of the other major players. How expensive is access? Well, I knew it was going to be a doozy when I had to contact them to get a quote for the API...

And boy was I right. To quote them directly: "Pricing for Search API access begins at USD $1,393.23 for up to 40,000 calls for the year. We can custom quote above 10,000,000 calls. For using Search API data, it would not be allowed to be redistributed, displayed, or integrated/cashed in an existing dataset, and would need to be refreshed every 72 hours." If I used their API, Ursula would cost me thousands per-year from the very beginning of the project, and costs would scale with users. For an open-source non-commercial project, this is a nonstarter.
Again, this is for book metadata, and OCLC is a nonprofit consortium of libraries and institutions. I'm not sure what's up with them, and I certainly have no broader context to speculate, but the cost seems absurd.
To put this in context, if you wanted to get the same information for movies, video games, or music, you'd be able to get this data in a high quality format, for free or at-cost, with no restrictions. It would seem intuitively to me that movies, games, and music, are much more closed in most cases than books - it's strange that this case should be different.
Regardless, I hate rent-seeking incumbents, so I'm determined to get around these data quality challenges at some point in the project (without forking over thousands to OCLC). Potential options include partnering with an institution, building my own database, or just putting a tremendous amount of work to make Google Books usable. I'm not sure - I've certainly gotten sucked down this rabbit hole enough already for such an early-stage project, so I'm going to force myself to stay on Google Books at least until I have the first beta out. If anybody has any experience in this area or suggestions, I'd love to hear from you!